
1·
2 days agoYou can self host location sharing. I do it with Nextcloud. Home assistant can do it too.
Nope. I don’t talk about myself like that.
You can self host location sharing. I do it with Nextcloud. Home assistant can do it too.
Cars don’t drive on sidewalks. Well… at least not usually. Though I guess I have to admit that I’ve seen it.

I read this too… This post should be removed for bullshit. It may be the original articles headline… but the headline is complete and utter garbage.

It’s a normal part of the military anyway… willy watching duty during drug tests is a thing. Gotta make sure the Joe isn’t cheating the drug test.
I don’t know what the other bathroom did… never asked or cared. But I will assume the stall door stayed open.
Your entire comment here is part of the reason this country is as broken as it is.
My comment was just on the facts. Not that I agreed with them.
So your insinuation and downvote, just shows that you make a lot of assumptions about people and I would argue that your post is way more damaging to the country than mine.
Edit: I’m not here arguing with you. I’m just outlining why you see it the way you do. I think it’s shit. But apparently you think I agree with the system just because it’s working for me. That’s not the case, and you’re the worse off for starting random hostility with people for it.
I didn’t misunderstand. You can’t claim you’re playing the credit game and only have one credit card and no non-revolving debts for years.
And no it hasn’t put you in a worse spot. “No credit” is effectively equivalent to “shitty score”. You didn’t need a cosigner when you were 20 because that was probably decades ago when credit score wasn’t used as a metric.

Wired headphones had the same benefit… Walk away too far and your phone is either yanking the buds out of your ears, or falling off whatever surface it was on, holding onto the cable for dear life.
I mean fair enough on the sentiment. I’m not particularly rich. But I do well off for myself and we live comfortably within our means.
But if you don’t “play the game” don’t be mad when you don’t score well? I know it sounds harsh, but it sounds to me like you don’t actually need credit access… so why do you care then?
One card at $5k limit (making this number up, only you know what you’re approved for on your card) doesn’t necessarily show worthiness for holding more debt. I have 4 active cards… aggregating about $40k of revolving limits. Of course rarely ever use them and pay them down.
Holding no non-revolving debts can actually hurt you. If you haven’t had a car note or mortgage in a long time, they don’t know if you’re capable of holding such debt effectively anymore. Before we bought a house, I specifically held onto the car notes and only paid the second car off after we secured the mortgage. Of course with a mortgage, I’ll be sitting on “debt” (really building equity in the house) for a while. but meeting the terms of that debt monthly only strengthens evidence that I can manage debt correctly, increasing score.
Edit: For you, try to increase your limits on your card. If not take out another card and make a purchase every few months on it to keep it active. As you increase the “allowances” you have, and keep that in check… you’ll find your number goes up quite quickly. As far as non-revolving debt, don’t take out a loan if you don’t need it, but think about sitting on a loan for your next purchase even if you have the cash on hand to build the credit up.
Has it though?
Yes it has… because I’ve attempted to take loans primarily under my wife who doesn’t hold as high a score as I do for a myriad of reasons. Same shared incomes… same shared assets. Only difference is my score is higher as far as they’re concerned.
Mine’s been consistently 800+ for years… and it has helped me considerably… repeatedly.
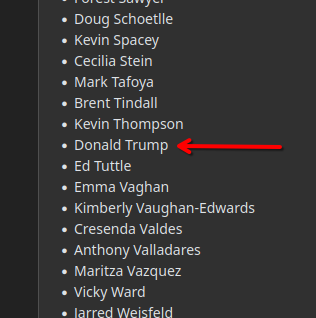
Trump is in the list… You could have read it.

Or even just the basic rules of math itself? Identity rule, Inverse rules, Commutative property, Associative property, Distributive property… There’s a lot of rules that prove and create stable ground for you to accept and understand PEMDAS/BODMAS.
Simply knowing one thing doesn’t prove that one thing.
All of these “rules” come up when you learn order of operations and have nothing to do with “advanced math classes”.
This shower thought seems grounded heavily in ignorance of math.

I think they all think it’s the legacy girls.
I guess because the colors are blue and pink that they’re going to somehow breed? But the “in game” answer is that it’s your characters “inspiration”.
Breed horse girls to create even better horse girls
I love how everyone believes that there’s breeding in this game… If you think there’s breeding… it’s literally in your head. You’re the problem.
Or kicking the “adequacy” into her head is what killed the last 2 brain cells she had.

Poland requires DigitalID or PESEL (National Identification Number, kinda like SSN for the yanks) number.
I’m still not entirely sure why these data centers require such massive amounts of water when we’ve been running heat exchange loops in nuclear plants for decades.
Because many are running evaporative cooling.
So the military has been bound by the same handcuffs that McDonalds is with it’s ice cream machines?
Yes… It’s funny because I worked on a platform called the MLRS. I saw what repairs to the circuitry of the GPS and other modules look like. I could have fixed it myself… by hand… The circuit boards were vietnam era looking stuff (the platform was from the 80’s, but developed during the 70s)… Meaning the trace pitch was measured in mm. Like I could pop open shit and eyeball and solder that shit with crappy $10 bargain bin soldering iron. But nah, needed to get a special civilian to show up and replace the board (they didn’t even try to fix it).


Pretty sure I read it.
You can do location sharing WITHOUT interacting with any “greedy company” or “highest bidder”.
Then you state…
and I confirm that you can do it in Nextcloud, and ALSO Home Assistant… as Home assistant is also likely to be something people are running.
I think that you think that everyone who ever comments to your post is always arguing against you.
Edit: missed a couple of words.