
Since version 118+, Firefox introduced FPP (Finger Printing Protection) which is in short water downed version of RFP (Resist Finger Printing).
FPP is enabled by default from version 119 onwards if you enable ETP (Enhanced Tracking Protection).
FPP randomizes canvas data subtly than RFP, which is why RFP breaks some sites. So, my question is, if we allow canvas data extraction for a broken site will it fallback to FPP’s subtle canvas randomization, or allowing it will expose canvas data completely if we have ETP enabled?
Relevant link: https://support.mozilla.org/en-US/kb/firefox-protection-against-fingerprinting
Edit: More info about HTML5 canvas fingerprinting https://webbrowsertools.com/canvas-fingerprint/
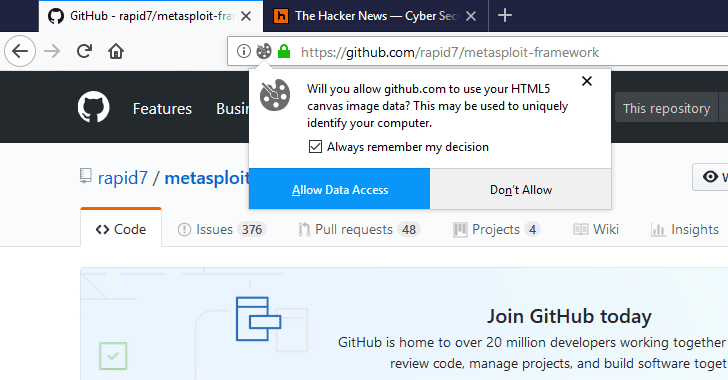
I can’t answer your question. But I’d like to know what these funny words mean. Can someone explain to me what is html5 canvas data and all the 3 letter words are?
https://coveryourtracks.eff.org/learn https://fingerprint.com/
RFP = I’m assuming he’s referring to the about:config setting in Firefox called privacy.resistFingerprinting. This blocks fingerprinting or at least does its best.
OPP = Assuming he’s referring to the other about:config setting privacy.resistFingerprinting.autoDeclineNoUserInput… It should work in coordination with the previous setting, overriding the previous restriction if you allow it.
Websites want to keep track of you without relying on cookies so they create an image with text in a canvas element, take the hash value of that and assign that as your unique id that will follow you every where you go on the internet.
Thanks for explainaing!
Why bother creating an image though? Cant they just generate a random hash or id?
I think the point is to get a consistent unique ID that follows you around. Whatever combination of text and images they are hashing will supposedly be unique to you, based on your hardware and software configuration.
the more you know, thanks.
https://webbrowsertools.com/canvas-fingerprint/ has got everything you need to know about html5 canvas.
I’ve only worked with canvas but not the security stuff, so I can only answer you partially.
Canvas is an element that you can create with HTML5, and the HTML5 canvas data just means what has been drawn on the canvas.
Now for the FPP, RFP stuff, I’m guessing they are some ways to encrypt the canvas. If the receiving end doesn’t decrypt it, the canvas is gonna be random noise.
(This part I’m really unsure about) Due to each client having a different key to encrypt and decrypt, this essentially allows others to track a certain user.
What is HTML5 canvas data, and how do websites track us, please?
Ah nah Canvas is used for so much stuff and it’s sometimes way under your radar in stuff you wouldn’t at all expect
For instance
- one-loop.github.io, opensource reddit front-end that allows you to look at reddit, but it looks like you’re reading outlook from a distance
- For people’s avatars, it sources images from thispersondoesnotexist.com
- You can’t just “download” a picture from another website, because that violates “CORS”: If it were allowed, you could just download their face from facebook.com, scan if they have something hosted on localhost, …
- You can use an <img> tag which fetches the image, but your javascript cannot access the image’s data. It doesn’t belong to your page
I’ll let you look at the comments to see how they circumvented this
async function generateFacePic(commentData: SnooComment, ppBuffer: HTMLImageElement[], displaySize: number = 50): Promise<HTMLCanvasElement> { const imageSeed = /* a random number */ const imageElement: HTMLImageElement = /* someone's avatar */ // Purpose of copying: A single <img> tag cannot be in multiple spots at the same time // I did not find a way to duplicate the reference to an img tag // If you use Element.appendChild with the same reference multiple times, the method will move the element around // Creating a new <img> tag and copying the attributes would work, but it would fetch the src again // The image at thispersondoesnotexist changes every second so the src points to a new picture now // Since the URL has a parameter and hasn't changed, then most likely, querying the URL again would // hit the browser's cache. but we can't know that. // Solution: make a canvas and give it the single <img> reference. It makes a new one every time. It doesn't query the src. const canv = copyImage2Canvas(imageElement, displaySize); canv.classList.add(`human-${imageSeed}`); return canv; }I’ve seen canvas being used for github-like random avatars, graphs, logos, to create dynamic previews of images on the page in online shops, …
On the topic of Reddit, trying to submit a video there with Canvas off would result in it being submitted with a glitched thumbnail
That’s a big one, generating thumbnails client-side rather than running an imagemagick instance on the server to re-size pictures on upload
I used it to generate hashes of the pictures as well, once.
Adding watermarks too. There are virtuous watermarks as well, I remember having to code up a transparents watermark over people’s IDs to make sure that when they submitted their renters dossier (it was a real estate renting service), it couldn’t be used to commit identity theft by the homeowner later down the line or re-used for something else.
RFP covers a lot more metrics than just the canvas, I don’t think it would fallback to FPP. You can test it on Arkenfox’s TZP test site to make sure though.

{kind=link}